我测了6个AI写小红书,最后只推荐这两个
分类:AI资讯 浏览量:51
摘要:
对6款AI工具进行两轮测试(从零生成与素材改写)后,核心结论:从零写首稿推荐元宝(网感强、像小红书运营)和千问(速度快、结构完整);有素材改写推荐Kimi(保真度高、改写像真人)和GPT(改写稳、适合做安全底稿);Claude适合最后一轮审稿查风险;豆包表达顺但流程稳定性一般,不适合自动化主力。测试聚焦出稿能力、是否乱编、改完能否发布,最终根据场景选择工具可提升效率。
先说结论。
如果你是从零写小红书首稿,优先试元宝和千问。
如果你已经有一篇文章,只是想改成小红书语言,优先试Kimi和GPT。
如果你要最后审稿、查风险,Claude可以放在最后一轮。
豆包表达很顺,但这次流程稳定性一般,不适合放进自动化流程里当主力。
这就是我测完6个AI后的最终判断。
这篇不讲玄学,也不吹模型能力。
我只关心三件事:
能不能出稿。
会不会乱编。
改完能不能发。
因为大部分人用AI写小红书,不是真的想研究AI。
你只是想更快拿到一篇能用的稿子。
所以我把同一个任务丢给了6个工具:
豆包、Kimi、元宝、千问、GPT、Claude。
测试时间是2026年6月1日。
测试分两轮。
第一轮,从零生成。
我给同一个主题:
普通职场人如何用AI把每天2小时重复工作压到20分钟。
让它们各写一篇小红书笔记。
第二轮,有素材改写。
我给一段已有公众号素材,让它们改成小红书笔记,并且明确要求:
不要自由编造工具名和数据。
这个区分很重要。
因为从零写和改已有稿,根本不是同一种能力。
从零写,看的是标题、情绪、平台语气、完整度。
改已有稿,看的是理解力、保真度、风险控制。
很多AI看起来都能写。
但真正一测,差距很明显。

同一任务输入截图:同题测试,避免只凭主观感受。
1. 元宝:最像小红书运营,但必须查它有没有加戏
元宝两轮都完成了。
第一轮约65.5秒,第二轮约53.5秒。
它最大的优点是:像小红书。
标题有钩子,正文有情绪,结尾有互动,还会主动给封面建议。
它会用「家人们」「谁懂啊」「打工人」这类平台语气。
你说这些词高级吗?不一定。
但它确实像一个小红书运营会写出来的稿子。
这点很实用。
因为很多AI写小红书最大的问题,不是不会写,而是写得太像公众号。
元宝的问题也很明显:它会加戏。
测试里,它会自己塞进一些我没有给的场景和工具名,比如会议纪要、飞书、通义听悟。
这些东西让文章看起来更丰富,但风险也在这里。
如果读者照着内容去找,发现不是这么回事,信任感就没了。
所以元宝适合做什么?
适合快速拿一版有网感、有情绪、有结构的首稿。
但发布前一定要逐行查:
有没有新增工具名。
有没有新增场景。
有没有夸张承诺。
有没有平台风险词。
元宝的优势是像。风险也是太像。

腾讯元宝:首稿网感强,但新增信息必须人工核查。
2. 千问:速度快、结构完整,适合日常量产
千问两轮都完成了。
第一轮约37.5秒,第二轮约34.3秒。
它是这次测试里速度和完整度都比较突出的工具。
标题、正文、封面建议、话题标签、风险核查点,一次性给齐。
这对真实工作很重要。
因为很多时候,你不是要AI写一篇多惊艳的文章。
你要的是一个能进发布流程的版本。
通义的优点可以概括成三个字:
快、全、稳。
它不像元宝那么冲,但也不是完全没平台感。
如果你是运营,或者一个人管几个账号,通义会比较省事。
问题是,它有时候会用一些偏猛的种草词。
比如「亲测」「拒绝加班」「神仙软件」。
这些词不是不能用,但如果整篇都这么写,就会显得像营销稿。
尤其是AI效率类内容,本来就容易被写得过满。
所以我的判断是:
千问适合日常量产首稿。
但发布前要把过度种草的词降下来。
不要让一篇工具测评,看起来像卖课广告。

千问:速度快、结构完整;左下角遮罩已重新修完整。
3. ChatGPT:改稿很稳,但从零写不够小红书
ChatGPT两轮完成。
第一轮有个小问题:按Enter没有提交,需要点发送按钮。
第二轮已有素材改写约38.6秒。
它的优势不是小红书网感。
它的优势是:稳。
尤其在第二轮。
我给它一段已有公众号素材,并要求不要编造工具名和数据。
它能保留原文核心观点:
不要让AI一键代替你。
而是把工作拆成找资料、搭结构、写初稿、改语气、做检查。
真实案例和最终判断,还是人来补。
这类内容,GPT处理得比较好。
但从零生成小红书时,它的小红书味不够。
结构清楚,观点也对,但更像公众号文章。
如果直接发小红书,点击和互动可能一般。
所以GPT的位置很明确:
不要指望它从零给你一篇很有网感的小红书。
但如果你已经有素材,想改成更安全、更清楚的版本,它很适合做保守底稿。

ChatGPT:已有素材改写更稳,适合做安全底稿。
4. Kimi:改写最像真人,但速度慢
Kimi两轮都完成了。
第一轮约103.9秒,第二轮约85.8秒。
它是这次最慢的一组。
但第二轮改写质量确实不错。
Kimi不像是在机械换个口吻。
它更像真的读懂了原素材,再重新组织成一篇经验分享。
保真度高,乱编少,风险表也比较完整。
如果你手里已经有一篇完整文章,想把它转成小红书语言,Kimi值得用。
但如果你要快速量产,Kimi不是最舒服的选择。
因为慢。
而且从零写的时候,它还是有点偏理性复盘。
小红书需要的标题冲突、情绪张力、开头钩子,还要人再补。
所以Kimi适合什么?
有素材、不赶时间、想要高保真改写。
它不适合当高速出稿机器。
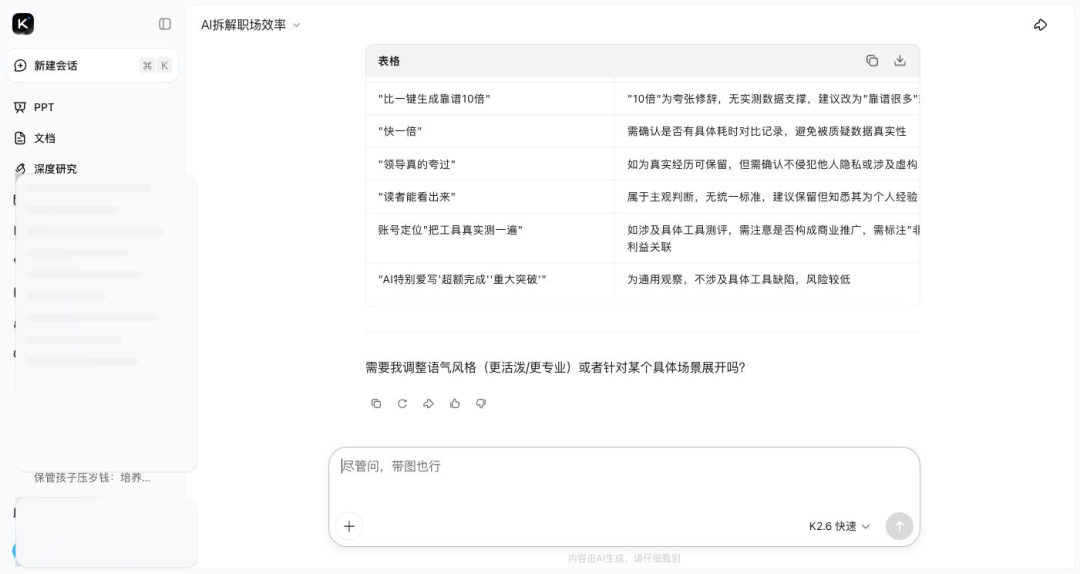
Kimi:已有素材改写质量高,但等待时间明显偏长。
5. 豆包:表达顺,但流程稳定性扣分
豆包这次过程比较曲折。
第一次没成功,补测后,普通对话模式下第一轮约45.1秒,结果可用。
豆包的内容本身不差。
表达顺,标题也有冲突感,正文、标签、风险点都能给。
但它的问题是流程不稳。
如果你只是偶尔手动用,问题不大。
但如果你想把它放进批量内容生产流程里,就会麻烦。
还有一个问题:它会出现「参考18篇资料」「零失误」这类表达。
这种句子看起来有说服力,但你没法验证。
平台也可能不喜欢。
所以豆包的位置是:
表达顺滑的备选工具。
但不适合作为自动化主力。

豆包:表达顺,但稳定性扣分。
6. Claude:适合审稿,不适合当首稿生成器
Claude两轮都测了。
第一轮约90.7秒,但没有完整按要求输出正文,只给了补充说明。
第二轮约54.5秒,改写完整。
Claude的优势是:认真、克制、会查风险。
它适合在文章已经有初稿之后,用来检查有没有夸张、跑偏、风险词。
但它不适合直接当小红书首稿生成器。
它的表达偏理性,平台感不够。
小红书上的用户不太这么说话。
所以我会把Claude放在最后一轮:
用来审稿,不用来起稿。
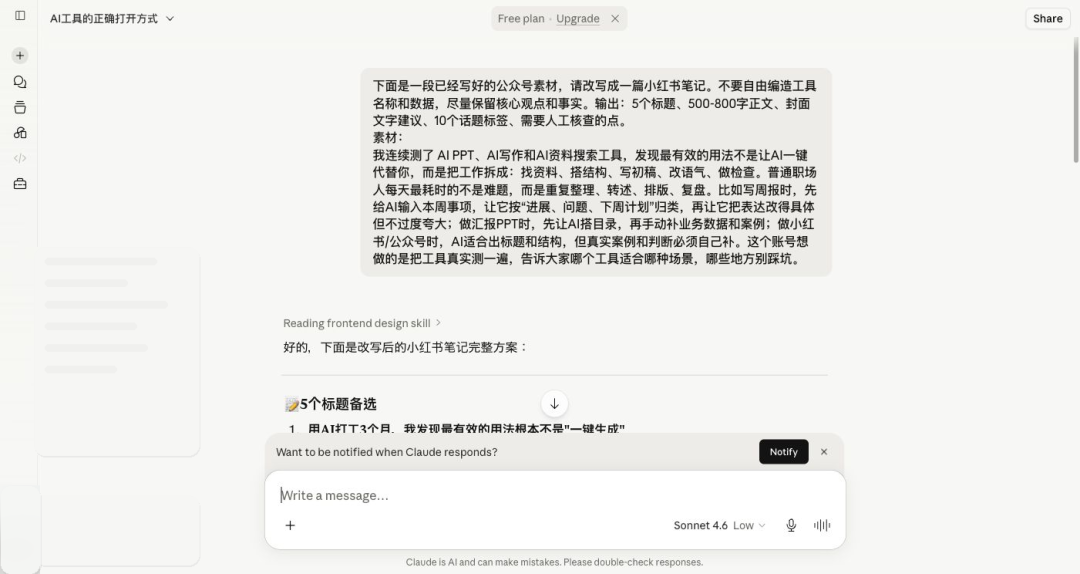
Claude:更像审稿助手,适合查风险,不适合直接出爆款首稿。
最后怎么选?直接给方案
如果你脑子里只有一个选题,想从零写小红书:
先用腾讯元宝。
它给你网感和方向。
如果你要更快、更完整:
用通义千问。
它适合日常量产。
如果你已经有一篇文章,想改成小红书:
先用Kimi。
它更像真的读懂了。
如果你要稳一点:
用ChatGPT。
它适合做安全底稿。
如果你要最终审稿:
用Claude。
它能帮你查风险和过度承诺。
如果你缺一版顺滑好读的表达:
豆包可以试。
但要接受流程不稳定。
我自己的建议流程是这样:
第一步,用元宝或千问出一版小红书感强的首稿。
第二步,用Kimi或ChatGPT根据原素材做保真改写。
第三步,人工合并,保留网感,删掉编造和夸张。
第四步,用Claude做风险审稿。
第五步,人来补真实截图、真实案例和最终判断。
这样出来的稿子,比让一个AI一键生成靠谱很多。
最后一句话
AI写小红书,不是选最强模型。
而是按环节分工。
别问哪个AI最强。
你要问的是:
我现在到底缺什么?
缺网感,就找元宝。
缺速度,就找千问。
缺保真,就找Kimi。
缺稳定,就找ChatGPT。
缺审稿,就找Claude。
缺顺滑表达,就找豆包。
这才是AI写作真正能提效的地方。
你现在最常用哪个AI写内容?
直接在评论区打一个工具名:豆包、Kimi、元宝、千问、ChatGPT或Claude。
如果你愿意,也可以顺手补一句:
它是帮你省时间,还是经常让你返工?
我会挑评论区提到最多的工具,下一篇继续做同题实测。